
The Processor’s Rhythm: How Pipelining Changed Computing
Overlapping Instructions, Pipeline Hazards, and the Architecture of Speed


Image from Pixabay on Pexels
Modern processors appear almost magical in their ability to execute billions of instructions every second. Applications launch instantly, videos stream smoothly, and complex calculations finish in moments. Beneath this illusion of effortless speed lies a carefully orchestrated system designed to keep the processor busy at every possible instant.
One of the most important innovations behind this performance revolution is pipelining.
Pipelining transformed processor design by changing a simple but powerful idea. Instead of waiting for one instruction to fully complete before starting the next, the processor overlaps multiple instructions at different stages of execution. Much like an assembly line in a factory, several operations move forward simultaneously, each occupying a different phase of the pipeline.
This technique dramatically improved processor throughput and became a cornerstone of modern computer architecture.
The Need for Faster Execution
Early processors executed instructions sequentially. An instruction would first be fetched from memory, then decoded, executed, and finally completed before the next instruction began.
Consider a simple sequence:
Fetch the instruction
Decode the instruction
Execute the operation
Store the result
If each step required one clock cycle, then one instruction would consume four cycles. The processor remained partially idle during much of this process because only one stage was active at a time.
As software became more demanding, this approach proved inefficient. Engineers needed a method to improve performance without merely increasing clock speed.
Pipelining provided the answer.
Understanding the Pipeline
A processor pipeline divides instruction execution into stages. Each stage performs a specific task and passes the partially processed instruction to the next stage.
A simplified five-stage pipeline usually includes:
Instruction Fetch
Instruction Decode
Execute
Memory Access
Write Back
Once the first instruction moves from fetch to decode, the fetch stage becomes free to retrieve the next instruction. After several cycles, multiple instructions occupy different stages simultaneously.
The result resembles a production line where several products are assembled at once rather than one after another.
A Simple Illustration
Without pipelining:

With pipelining:
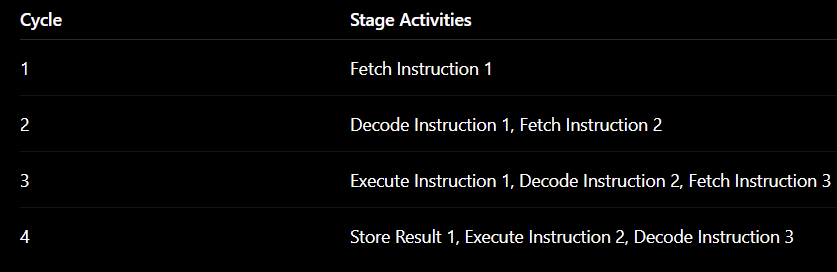
The processor now handles several instructions concurrently.
Throughput Versus Latency
Pipelining improves throughput rather than reducing the execution time of an individual instruction.
An analogy helps clarify this distinction.
Imagine a laundry system with washing, drying, and folding stages. One load of clothes still requires the same total time to complete all stages. However, multiple loads can move through the system simultaneously, increasing the number of completed loads per hour.
Similarly, pipelining increases the number of instructions completed over time.
Pipeline Depth and Modern Designs
As processor technology advanced, pipelines became deeper.
A deeper pipeline divides work into smaller stages. Since each stage performs less work, the processor can operate at higher clock frequencies. Some processors historically used extremely deep pipelines to maximise clock speed.
However, deeper pipelines introduced new complications. When problems occur, more partially executed instructions must be corrected or discarded. This increases performance penalties.
Designers, therefore, balance pipeline depth carefully.
Pipeline Hazards
Although pipelining improves efficiency, it also introduces situations where instructions interfere with one another. These situations are called hazards.
Hazards prevent the next instruction from executing smoothly within the pipeline.
There are three major categories:
Structural Hazards
Data Hazards
Control Hazards
Each represents a different kind of conflict inside the processor.
Structural Hazards: Resource Conflicts
A structural hazard occurs when multiple instructions require the same hardware resource simultaneously.
Imagine two instructions, both needing access to memory during the same clock cycle. If the processor contains only one memory access unit, one instruction must wait.
This resembles traffic merging into a single lane road.
Example
Instruction A accesses memory for data
Instruction B fetches a new instruction
Both require memory simultaneously
If the architecture lacks separate pathways, the pipeline stalls temporarily.
Solutions
Processor designers reduce structural hazards through hardware duplication and smarter resource allocation.
Common solutions include:
Separate instruction and data caches
Multiple execution units
Improved scheduling mechanisms
Modern processors are heavily engineered to minimise these conflicts.
Data Hazards: Dependency Problems
Data hazards arise when instructions depend on results produced by earlier instructions.
Consider the following operations:
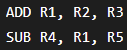
The subtraction instruction depends on the updated value of R1 generated by the addition instruction.
If the subtraction executes before the addition completes, it may use outdated data.
Types of Data Hazards
Read After Write
This is the most common form.
An instruction tries to read data before a previous instruction writes it.
Write After Read
A later instruction overwrites data before an earlier instruction finishes reading it.
Write After Write
Two instructions attempt to write to the same location in the wrong order.
Handling Data Hazards
Processors employ several techniques to manage dependencies.
Pipeline Stalls
The processor pauses certain stages until the required data becomes available.
Although effective, stalls reduce performance because portions of the pipeline become idle.
Data Forwarding
Forwarding sends results directly from one pipeline stage to another without waiting for full completion.
This avoids unnecessary delays.
Register Renaming
Modern processors often eliminate false dependencies by dynamically assigning temporary internal registers.
This technique enables greater parallelism and improves efficiency.
Control Hazards: The Cost of Decision Making
Control hazards emerge from branch instructions such as conditional jumps and loops.
A processor fetches instructions continuously, but a branch changes the program’s direction. Until the branch condition is evaluated, the processor may not know which instruction comes next.
This creates uncertainty inside the pipeline.
Example
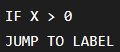
The processor must determine whether the jump occurs before fetching the correct next instruction.
If it guesses incorrectly, partially executed instructions must be discarded.
This process is known as a pipeline flush.
Branch Prediction
To reduce delays, modern processors predict branch outcomes before they are confirmed.
Sophisticated branch predictors analyse previous execution patterns and estimate future behaviour with remarkable accuracy.
Correct predictions keep the pipeline flowing smoothly.
Incorrect predictions introduce penalties because incorrectly fetched instructions must be removed.
Speculative Execution
Many processors go even further by executing predicted instructions before branch decisions are finalised.
If the prediction proves correct, performance improves significantly.
If the prediction fails, speculative work is discarded.
This technique demonstrates how modern processors prioritise speed, sometimes at considerable architectural complexity.
Pipeline Performance Gains
The primary advantage of pipelining is improved instruction throughput.
In an ideal pipeline:
One instruction completes every clock cycle after the pipeline fills
Processor utilisation increases dramatically
Overall execution efficiency improves
The theoretical speedup roughly approaches the number of pipeline stages.
For example, a five-stage pipeline could theoretically provide close to five times the throughput of a non-pipelined processor.
Real-world performance is lower because hazards and stalls introduce inefficiencies.
Still, pipelining remains one of the most successful performance-enhancing techniques in computing history.
Superscalar and Out of Order Execution
Modern processors extend pipelining further through advanced techniques.
Superscalar Execution
Superscalar processors issue multiple instructions simultaneously across several pipelines.
Instead of completing one instruction per cycle, they may complete several.
Out of Order Execution
Instructions are dynamically rearranged so independent operations execute earlier, while waiting instructions are delayed.
This keeps execution units active and reduces idle time.
Together, these techniques allow processors to exploit instruction-level parallelism at extraordinary scales.
The Hidden Complexity Beneath Simplicity
To software developers, processors often appear straightforward. Programs are written as sequential instructions that execute one after another.
Internally, however, the processor behaves very differently.
Instructions overlap, reorder, speculate, stall, forward data, predict branches, and compete for resources. The clean illusion of sequential execution is maintained only through immense architectural sophistication.
Pipelining sits at the centre of this transformation.
In conclusion, pipelining changed computer architecture by teaching processors how to work on multiple instructions simultaneously. By overlapping execution stages, processors dramatically increased throughput and unlocked new levels of computational performance.
Yet this improvement introduced complexity in the form of hazards, dependencies, and prediction challenges. Modern processors devote enormous engineering effort toward managing these issues efficiently.
The result is a delicate balance between speed and coordination.
Every modern application, from gaming engines to scientific simulations, depends on processors that continuously juggle thousands of overlapping operations with astonishing precision.
What appears to users as effortless speed is, in reality, the carefully synchronised rhythm of the processor pipeline.