
The Thinking Processor: Superscalar and Out of Order Execution
How Modern Processors Execute More Than One Instruction at a Time


Image from Pixabay on Pexels
For decades, the central challenge of processor design appeared deceptively simple. Computers needed to execute instructions faster. Early processors improved performance mainly by increasing clock speeds. A processor running at 2 GHz was naturally faster than one running at 1 GHz, much like a car moving at 120 kilometres per hour will usually arrive sooner than one travelling at 60.
But this straightforward approach eventually collided with physical reality. Higher clock speeds generated more heat, consumed more power, and created diminishing returns. Engineers could no longer rely solely on faster clocks to improve computing performance. They needed processors that were not merely faster, but smarter.
This necessity gave rise to some of the most important innovations in computer architecture: superscalar execution and out-of-order execution. These techniques transformed the processor from a rigid instruction follower into a highly adaptive execution engine capable of analysing, predicting, and reorganising work in real time.
Modern CPUs no longer process instructions one at a time in neat sequence. Instead, they resemble highly coordinated factories where multiple tasks are examined simultaneously, reordered dynamically, and executed whenever resources become available.
Understanding these optimisations is essential to understanding modern computing itself.
The Limits of Sequential Execution
At the heart of every processor lies the instruction cycle. A CPU fetches an instruction from memory, decodes it, executes it, and then moves on to the next instruction.
In the earliest processors, this process was strictly sequential.
Fetch instruction A
Execute instruction A
Fetch instruction B
Execute instruction B
This design was simple but inefficient. Many processor components remained idle while waiting for certain operations to complete. For example, if one instruction required memory access that took several cycles, the rest of the processor often sat inactive.
To solve this inefficiency, architects first introduced pipelining.
A pipeline divides instruction execution into stages so multiple instructions can overlap. While one instruction is being executed, another can be decoded, and a third can be fetched from memory.
Pipelining improved performance significantly, but another problem remained.
Even within a pipeline, many hardware units still waited idly because instructions were processed in strict order. The processor needed a way to execute multiple instructions simultaneously and avoid unnecessary waiting.
This need led to superscalar architecture.
Superscalar Execution: Multiple Instructions at Once
A superscalar processor can issue and execute more than one instruction during a single clock cycle.
Instead of having only one execution path, the CPU contains multiple execution units operating in parallel.
Imagine a restaurant kitchen with only one chef. Every dish must be prepared one after another. Now imagine a larger kitchen with several chefs working simultaneously on different tasks. More meals can be prepared within the same amount of time.
A superscalar processor functions similarly.
If the instructions are independent, the CPU may execute several of them together:
One arithmetic operation
One memory load
One branch calculation
One floating-point computation
all during the same cycle.
This dramatically increases instruction throughput.
Multiple Execution Units
Modern processors contain specialised hardware units such as:
Integer arithmetic units
Floating point units
Load and store units
Branch units
Vector processing units
A superscalar design allows the processor to dispatch instructions to these units simultaneously.
For example:
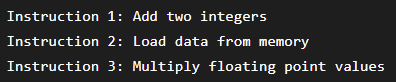
Since these tasks use different hardware units, they can often execute in parallel.
The processor, therefore, completes more work without increasing clock speed.
The Challenge of Dependencies
Superscalar execution sounds ideal in theory, but software instructions are rarely independent.
Consider the following sequence:
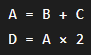
The second instruction depends on the result of the first. The processor cannot compute D until A has been calculated.
These relationships are called data dependencies.
Dependencies create execution bottlenecks because some instructions must wait for earlier ones to finish.
If processors obey strict program order, valuable hardware resources remain idle during these waits.
To overcome this limitation, architects introduced one of the most sophisticated concepts in processor design: out-of-order execution.
Out of Order Execution: Breaking Sequential Rigidity
Out-of-order execution allows the processor to execute instructions as soon as their required data becomes available, rather than strictly following program order.
The CPU dynamically rearranges instructions internally while preserving the correct final result.
This is one of the defining characteristics of modern high-performance processors.
An Everyday Analogy
Imagine a bank with multiple service counters.
Customers arrive in sequence, but not all transactions require the same amount of time. One customer may need only a quick deposit, while another requires lengthy paperwork.
If every customer had to wait strictly in order, many counters would remain idle whenever a slow transaction blocked the queue.
A smarter bank allows independent customers to move ahead if a counter becomes available.
Out-of-order execution applies the same principle inside the processor.
Instructions that are ready can proceed immediately, even if earlier instructions are still waiting for data.
How Out of Order Execution Works
Modern processors use several advanced mechanisms to make this possible.
Instruction Window
The CPU examines a group of upcoming instructions simultaneously rather than focusing only on the next one.
This collection is called the instruction window.
The processor analyses dependencies within this window to identify which instructions can execute independently.
Register Renaming
One major challenge involves false dependencies.
Sometimes two instructions use the same register name even though their data is unrelated. This creates artificial conflicts.
Register renaming solves this by mapping logical registers to different physical registers internally.
This allows unrelated instructions to execute simultaneously without interference.
Reservation Stations
Instructions waiting for operands are placed into reservation stations.
As soon as their required inputs become available, they are dispatched to execution units automatically.
This enables continuous hardware utilisation.
Reorder Buffer
Although instructions execute out of order internally, the processor must preserve correct program behaviour externally.
The reorder buffer ensures that completed instructions are committed in the original program order.
This preserves correctness while still allowing aggressive optimisation internally.
Branch Prediction: Guessing the Future
Modern processors face another major obstacle: branches.
Programs constantly make decisions.
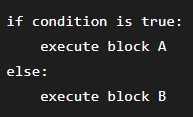
The CPU cannot know immediately which path will be taken because it must first evaluate the condition.
Without optimisation, the pipeline would stall frequently while waiting for branch results.
Branch prediction solves this problem.
The processor predicts which path is most likely and begins executing instructions ahead of time.
If the prediction is correct, performance improves dramatically.
If the prediction is wrong, the speculative work is discarded, and execution restarts from the correct path.
Modern branch predictors are astonishingly accurate, often exceeding 95 percent accuracy in common workloads.
Speculative Execution
Branch prediction naturally leads to speculative execution.
The processor performs work before it knows with certainty that the work is actually needed.
This may seem risky, but it allows the CPU to keep execution units busy rather than waiting idly.
Speculative execution became one of the defining features of modern superscalar processors.
However, it also introduced unexpected security vulnerabilities decades later, most famously in the form of the Spectre and Meltdown attacks.
These attacks demonstrated that performance optimisations can sometimes expose subtle side effects invisible to software developers.
Instruction Level Parallelism
Superscalar and out-of-order execution both rely heavily on instruction-level parallelism.
This refers to how many independent instructions exist within a program at a given time.
Some workloads naturally contain abundant parallelism.
For example:
Multimedia processing
Scientific simulations
Graphics rendering
Artificial intelligence computations
Other workloads contain frequent dependencies that limit simultaneous execution.
Processor designers constantly attempt to extract as much parallelism as possible automatically, even from ordinary software.
This is one reason modern CPUs are extraordinarily complex beneath the surface.
Micro Operations and Instruction Decoding
Modern processors often translate complex instructions into smaller internal operations called micro operations or micro ops.
For example, a single machine instruction may internally become several simpler steps.
This translation allows the processor to optimise scheduling more effectively.
Internally, many modern CPUs behave less like traditional instruction machines and more like sophisticated micro-operation processing engines.
This internal abstraction layer gives architects enormous flexibility in execution design.
Cache Optimisation and Memory Scheduling
Processor speed is meaningless if the CPU constantly waits for memory.
Modern architectures, therefore, devote enormous effort to reducing memory latency.
Cache Hierarchies
Processors use multiple layers of cache memory:
L1 cache for extremely fast access
L2 cache for larger but slower storage
L3 cache shared across cores
Frequently used data is stored closer to the processor to reduce access delays.
Prefetching
Modern CPUs attempt to predict which data will be needed next and load it into cache before the program requests it.
This process is called prefetching.
Good prefetching significantly improves performance by reducing waiting time.
Memory Reordering
Processors may also reorder memory operations internally to improve efficiency while maintaining program correctness.
This requires sophisticated consistency mechanisms, especially in multicore systems.
The Rise of Multicore Processors
Eventually, architects realised that extracting additional instruction-level parallelism alone would not sustain indefinite performance growth.
The industry, therefore, shifted toward multicore processors.
Instead of one extremely complex core, processors began including multiple independent cores on the same chip.
Each core may independently use:
Superscalar execution
Out-of-order execution
Speculative execution
Branch prediction
This created another layer of parallelism called thread-level parallelism.
Modern computing performance now depends on both intelligent single-core optimisation and efficient multicore coordination.
Why Modern CPUs Are So Complex
A modern high-performance processor contains billions of transistors.
Much of this complexity exists not because instructions themselves are difficult, but because extracting maximum efficiency from instruction streams is extraordinarily challenging.
The processor must constantly:
Predict future behaviour
Detect dependencies
Reorder operations
Manage speculation
Avoid hazards
Coordinate memory access
Maintain correctness
all within fractions of a nanosecond.
In many ways, modern CPUs resemble dynamic scheduling systems more than simple calculators.
Their intelligence lies not only in computation, but in orchestration.
In conclusion, superscalar and out-of-order execution fundamentally changed the philosophy of processor design.
Early processors focused mainly on executing instructions correctly. Modern processors focus equally on executing them efficiently.
The CPU no longer waits passively for one instruction to finish before considering the next. Instead, it studies streams of instructions, predicts future paths, rearranges operations dynamically, and keeps multiple hardware units active simultaneously.
These optimisations transformed computing performance without relying entirely on higher clock speeds.
Today, whenever a smartphone processes video smoothly, a game renders complex worlds instantly, or a laptop compiles millions of lines of code in seconds, these architectural innovations are working invisibly beneath the surface.
Modern processors are not simply faster machines.
They are machines that have learned how to anticipate, adapt, and exploit parallelism at an extraordinary scale.